"A lamp imitating an apple."
"A lamp imitating an avocado."
"A lamp imitating an umbrealla."
"A lamp imitating a teddy bear."
"A lamp imitating a mushroom"
"A lamp imitating a rabbit."
"A lamp imitating a shell."
"A lamp with a rainbow texture"
"A green bedside lamp"
"A lamp imitating a banana."
Abstract
Generating 3D shapes using text guidance is a challenging task due to the lack of large paired text-shape datasets, the significant semantic gap between these two modalities, and the structural complexity of 3D shapes. In this paper, we introduce a novel framework, called Image as Stepping Stone (ISS), that employs 2D images as stepping stone to connect the two modalities, eliminating the need for paired text-shape data. Our key contribution is a two-stage feature-space alignment approach that leverages a pre-trained single-view reconstruction (SVR) model to map CLIP features to shapes: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space by encouraging consistency between the input text and rendered images. We also propose a text-guided shape stylization module that can enhance the output shapes with novel structures and textures. Additionally, our approach is flexible. It can be used with various SVR models to further enhance the generative scope and quality. Our extended approach, DreamStone, leverages pre-trained text-to-image diffusion models to enhance the generative diversity, fidelity, and stylization capability. Also, it can further expand our generative scope beyond the image dataset. Our experimental results demonstrate that our approach outperforms the state-of-the-art methods and our baselines in terms of fidelity and consistency with text. Additionally, our approach can stylize the generated shapes with both realistic and fantastical structures and textures.
Method
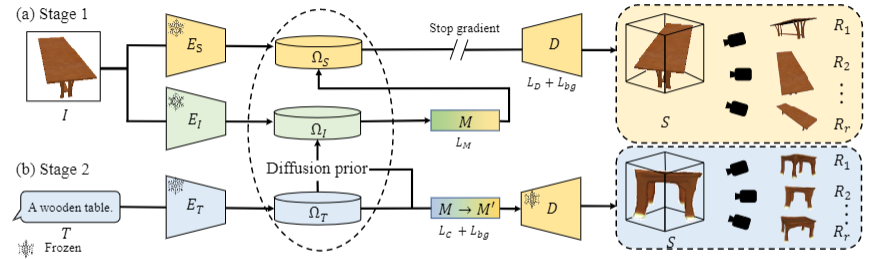
Two-stage feature-space alignment: (a) In the first stage, we leverage a pre-trained single-view reconstruction (SVR) model to align the feature spaces of the CLIP image feature space $\Omega_{\text{I}}$ and the shape space $\Omega_{\text{S}}$ of the SVR model. We train the CLIP2Shape mapper $M$ to map images to shapes while keeping $E_\text{S}$ and $E_\text{I}$ frozen, and fine-tune the decoder $D$ using an additional background loss $L_{\text{bg}}$. During training, we stop the gradients from the SVR loss $L_D$ and the background loss $L_{\text{bg}}$ propagating to $M$. (b) In the second stage, we fix the decoder $D$ and fine-tune the mapper $M$ to $M'$ by encouraging CLIP consistency between the input text $T$ and the rendered images at test time.
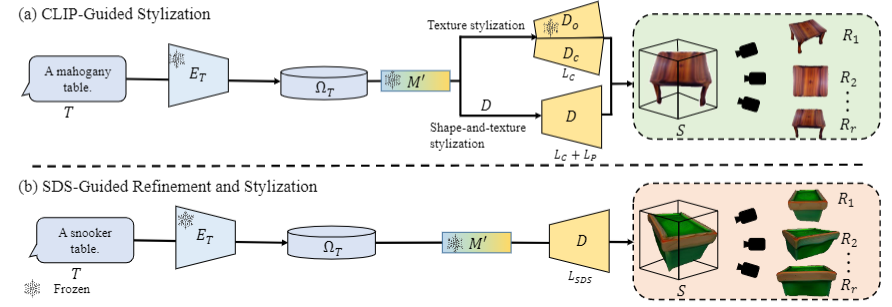
Text-guided stylization and refinement.
Reference
@article{liu2023dreamstone,
title={DreamStone: Image as Stepping Stone for Text-Guided 3D Shape Generation},
author={Liu, Zhengzhe and Dai, Peng and Li, Ruihui and Qi, Xiaojuan and Fu, Chi-Wing},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2023}
@article{liu2023iss,
author = {Liu, Zhengzhe and Dai, Peng and Li, Ruihui and Qi, Xiaojuan and Fu, Chi-Wing},
title = {ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation},
journal = {International Conference on Learning Representations (ICLR)},
year = {2023},
}