Abstract
This paper presents a new text-guided technique for generating 3D shapes. The technique leverages a hybrid 3D shape representation, namely EXIM, combining the strengths of explicit and implicit representations. Specifically, the explicit stage controls the topology of the generated 3D shapes and enables local modifications, whereas the implicit stage refines the shape and paints it with plausible colors. Also, the hybrid approach separates the shape and color and generates color conditioned on shape to ensure shape-color consistency. Unlike the existing state-of-the-art methods, we achieve high-fidelity shape generation from natural-language descriptions without the need for time-consuming per-shape optimization or reliance on human-annotated texts during training or test-time optimization. Further, we demonstrate the applicability of our approach to generate indoor scenes with consistent styles using text-induced 3D shapes. Through extensive experiments, we demonstrate the compelling quality of our results and the high coherency of our generated shapes with the input texts, surpassing the performance of existing methods by a significant margin. Codes and models are released at https://github.com/liuzhengzhe/EXIM.
Method
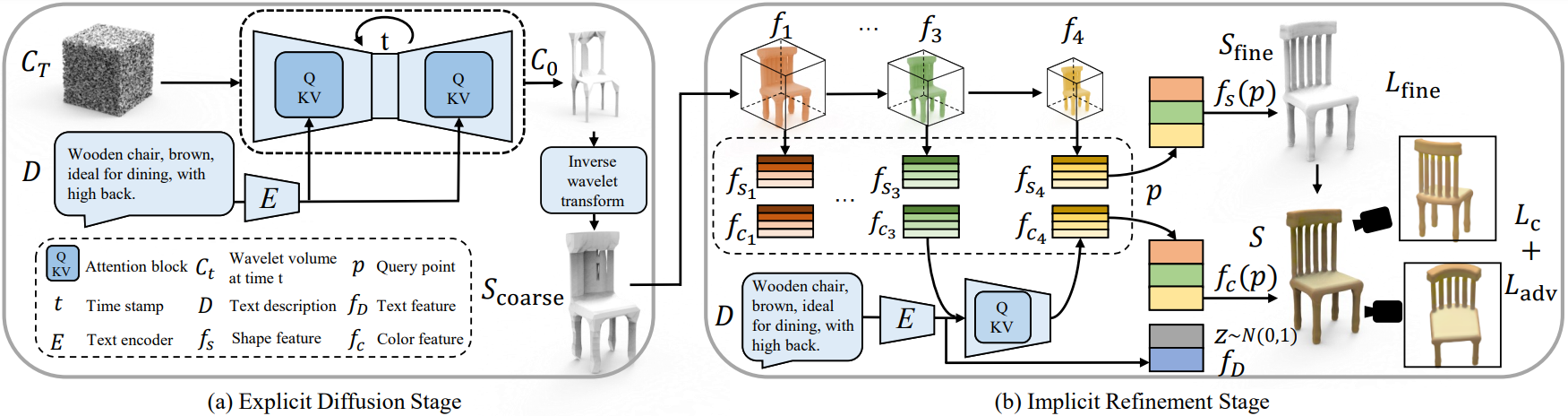
Overview of our approach. (a) The Explicit Diffusion Stage transforms the truncated signed distance field (TSDF) of the training shape $S$ into compact wavelet volumes $C$ and utilizes a 3D diffusion model with the U-Net architecture to learn the coarse shape $S_\text{coarse}$ conditioned on the text description $D$ with cross-attention modules. (b) The Implicit Refinement Stage refines the coarse shape $S_\text{coarse}$ to produce the fine shape $S_\text{fine}$ and generates colors on the surface to create the final result $S$. It employs a 3D convolutional encoder to extract features from multi-level feature maps and predicts the occupancy and RGB values at each query location $p$. The color prediction is also conditioned on the text $D$ using cross-attention modules.

Our pipeline for modifying (a) shape and (b) color. For shape, we expand the diffusion model to include two additional input channels, the mask $M$ and the unmasked partial shape $S^\prime$. We then fine-tune the model to fill in the masked areas. For color, we can either incorporate the new text features into the intermediate feature maps or directly generate color values within the regions specified by $M$, without the need for fine-tuning.
Reference
@article{liu2023exim,
title={EXIM: A Hybrid Explicit-Implicit Representation for Text-Guided 3D Shape Generation},
author={Liu, Zhengzhe and Hu, Jingyu and Ka, Hei-Hui and Qi, Xiaojuan and Daniel, Cohen-Or and Fu, Chi-Wing},
journal={ACM Transactions on Graphics (TOG)},
volume={42},
number={6},
year={2023}